




标题:Hive数据实时导入:高效解决方案与实践技巧
随着大数据时代的到来,数据量呈爆炸式增长,如何高效地处理和分析海量数据成为了企业关注的焦点。Hive作为一款强大的数据仓库工具,在处理大规模数据集方面具有显著优势。本文将详细介绍Hive数据实时导入的方法和技巧,帮助您实现高效的数据处理。
一、Hive数据实时导入概述
- 什么是Hive?
Hive是一款建立在Hadoop之上的数据仓库工具,可以将结构化数据存储在Hadoop文件系统中,并提供类似SQL的查询功能。它适用于处理大规模数据集,支持多种数据格式,如文本、JSON、XML等。
- 为什么需要实时导入?
实时导入数据可以确保数据仓库的实时性,为业务决策提供及时、准确的数据支持。实时导入有以下优势:
(1)提高数据处理的效率,缩短数据处理周期;
(2)降低数据延迟,为业务决策提供更准确的数据;
(3)提高数据仓库的可用性,满足业务需求。
二、Hive数据实时导入方法
- 使用Sqoop进行实时导入
Sqoop是一款开源的数据迁移工具,可以将结构化数据在Hadoop和关系型数据库之间进行迁移。通过Sqoop,可以实现Hive数据实时导入。
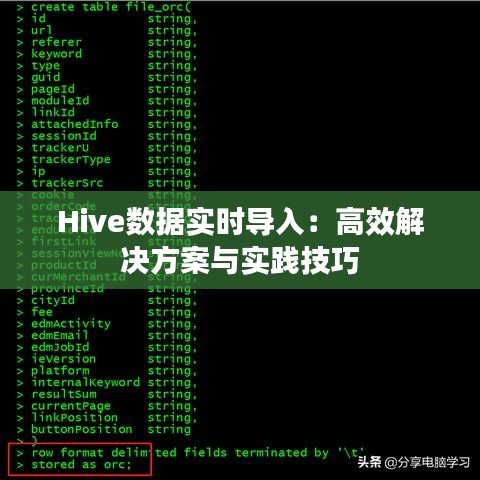
(1)配置Sqoop
首先,需要在Hadoop集群中安装并配置Sqoop。配置内容包括:
① 配置Hadoop环境变量; ② 配置数据库连接信息; ③ 配置Sqoop参数。
(2)编写Sqoop命令
编写Sqoop命令,实现数据迁移。以下是一个示例:
sqoop import --connect jdbc:mysql://localhost:3306/database_name --username username --password password --table table_name --target-dir /user/hive/warehouse/database_name.db/table_name --as-textfile --input-fields-terminated-by '\t' --input-null-string '\\N' --input-null-non-string '\\N' --hive-overwrite- 使用Flume进行实时导入
Flume是一款分布式、可靠、可用的数据收集系统,可以将日志数据实时传输到Hive。通过Flume,可以实现Hive数据实时导入。
(1)配置Flume

首先,需要在Hadoop集群中安装并配置Flume。配置内容包括:
① 配置数据源; ② 配置数据传输通道; ③ 配置数据目的地。
(2)编写Flume配置文件
编写Flume配置文件,实现数据传输。以下是一个示例:
agent.sources = source1
agent.sinks = sink1
agent.channels = channel1
# 配置数据源
agent.sources.source1.type = exec
agent.sources.source1.command = tail -F /path/to/logfile.log
agent.sources.source1.channels = channel1
# 配置数据传输通道
agent.channels.channel1.type = memory
agent.channels.channel1.capacity = 1000
agent.channels.channel1.transactionCapacity = 100
# 配置数据目的地
agent.sinks.sink1.type = hdfs
agent.sinks.sink1.hdfs.path = /user/hive/warehouse/database_name.db/table_name
agent.sinks.sink1.hdfs.filePrefix = log-
agent.sinks.sink1.hdfs.round = true
agent.sinks.sink1.hdfs.roundValue = 10
agent.sinks.sink1.hdfs.roundUnit = minute
agent.sinks.sink1.hdfs.rollCount = 0
agent.sinks.sink1.hdfs.rollSize = 0
agent.sinks.sink1.hdfs.rollTime = 0
agent.sinks.sink1.hdfs.maxOpenFiles = 1000
agent.sinks.sink1.hdfs.writeFormat = TEXT
agent.sinks.sink1.hdfs.fileType = DataStream- 使用Kafka进行实时导入
Kafka是一款分布式流处理平台,可以实现高吞吐量的数据传输。通过Kafka,可以实现Hive数据实时导入。
(1)配置Kafka
首先,需要在Hadoop集群中安装并配置Kafka。配置内容包括:
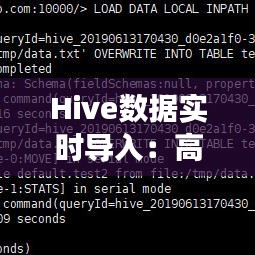
① 配置Kafka集群; ② 配置Kafka生产者; ③ 配置Kafka消费者。
(2)编写Kafka生产者
编写Kafka生产者代码,实现数据生产。以下是一个示例:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
String topic = "hive_topic";
String data = "data_to_import";
producer.send(new ProducerRecord<>(topic, data));
producer.close();(3)编写Kafka消费者
编写Kafka消费者代码,实现数据消费。以下是一个示例:
Properties props = new Properties();
props.put("bootstrap.servers", "转载请注明来自安平县港泽丝网制造有限公司,本文标题:《Hive数据实时导入:高效解决方案与实践技巧》






 冀ICP备2020022719号-3
冀ICP备2020022719号-3